神经网络优化任务的一般描述
一个估计器可以描述为如下形式. 其中Θ是参数集合, x和y^分别是输入和输出.
y^=f(x,Θ)
而学习目标则要求最小化损失函数J
minΘJ(Θ,x,y)
如果J是比较简单的形式, 如感知机中的均方误差MSE, 那么可以将J视为θ的函数, 直接求导后使用梯度下降进行最优化求解. 下式中的λ为学习率.
θ←θ−λ∇θJ(θ),∀θ∈Θ
为方便理解, 可以将θ视为自变量, 而x和y视为损失函数的参数.
但是如果J是比较复杂的形式, 比如是某个θ∈Θ的复合函数, 甚至对每个参数θ的复合层级并不一致, 那么无法直接求得J对θ的偏导数. 多层神经网络就是一个例子. 在这种情况下, 就需要用到反向传播(BP)算法.
BP算法一般形式的推导
首先回忆一下复合函数求导法则和多元复合函数求导法则:
∇xf(g(x))∇xf(g(x),h(x))=∂g∂f∂x∂g=∂g∂f∂x∂g+∂h∂f∂x∂h
考虑如下图所示的神经元, 其中一个神经元的输出被多个不同分支的神经元作为输入(当然也可以是一个或者没有).
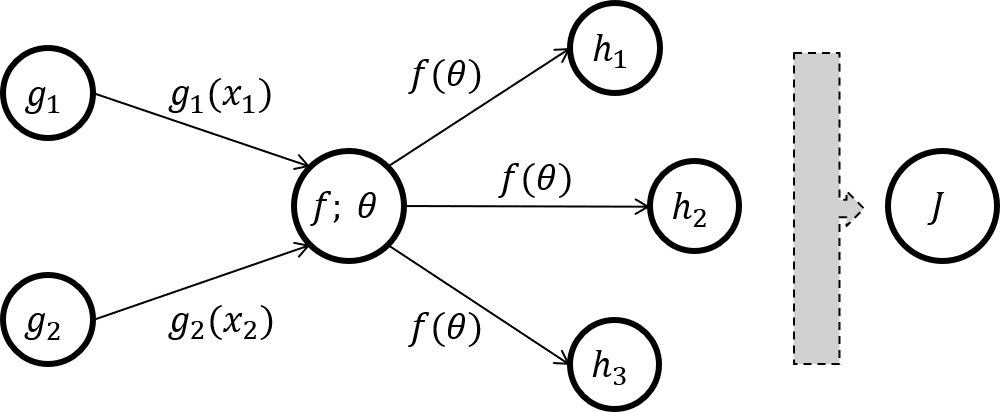
这里的损失函数可以表示为f,h的多元复合函数
J(θ)=J(h1(f(θ)),h2(f(θ)),h3(f(θ)))=J(h(f(θ)))
那么损失函数对参数θ的偏导数呼之欲出
∇fJ∇θJ=∂h1∂J∂f∂h1+∂h2∂J∂f∂h2+∂h3∂J∂f∂h3=∇hJ⋅∇fh=∂f∂J∂θ∂f=(∇hJ⋅∇fh)∇θf
整理一下便可以得到本文结论(典型的动态规划递推公式)
∇fJ∇θJ=∇hJ⋅∇fh=∇fJ∇θf,,ResidualGradience to parameter θ
可见损失函数J对参数θ的梯度可以分为三个要件:
- ∇hJ 这个向量是损失函数对f所有直接后继节点的梯度
- ∇fh 这个向量是f的所有直接后继节点对f本身的梯度
- ∇θf 这个数值就是f对参数θ的梯度
注意前两个部分的点积组成了损失函数对f本身的梯度, 而这一梯度会在节点f的直接前驱节点的BP过程中使用到.
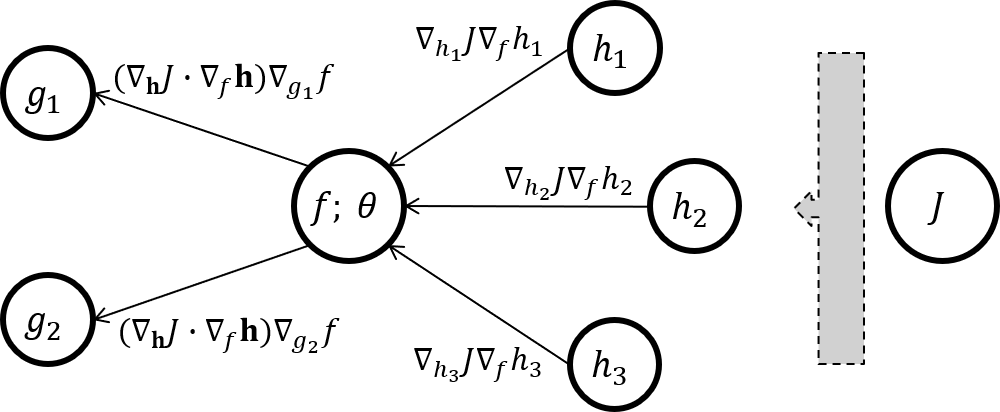
实际BP应用举例
在实际应用的时候, 也就是自定义一个神经网络的层的时候, 最需要注意的是, 只需要关心:
- 本层传递给后继层的输出是什么? (其shape必然仅与本层相关)
- 得到后继层反传来的残差后, 本层应该如何计算梯度并更新参数? (梯度的shape必然仅与本层参数的shape相关)
- 得到后继层反传来的残差后, 本层反传给前驱层的残差是什么? (其shape必然仅与本层的输入相关)
前馈全连接网络
如果前馈全连接网络的输入是x0, 输出是y, 网络包含n+1层, 第i层的参数矩阵为Θi, 则网络可以表示为
x1x2xny^=f0(x0,Θ0)=f1(x1,Θ1)…=fn−1(xn−1,Θn−1)=fn(xn,Θn)
其中, 如果对于某一层i, 其前驱, 本身, 后继层的节点个数分别为l,m,n, 那么
fi(xi,Θi)={Θixi,Θi∈Rm×l,xi∈Rl,max(0,xi),xi∈Rl,如果是连接层如果是激活层且使用relu
而目标为最小化损失函数
minΘ0,…,ΘnJ(x0,y,Θ0,Θ1,…,Θn−1,Θn)
为方便理解, 这里将∇fiJ简写为∇i. 对第i层套用BP过程的结论
∇i∇ΘiJ=ϕ(∇fifi+1,∇i+1)=ϕ(∇xi+1fi+1,∇i+1)∈Rm=∇i⊗∇Θifi∈Rm×l
其中
ϕ(A,b)∇xi+1fi+1∇Θifi={ATb(matrix-vector product)A∘b(entry-wise product)如果第i+1层是连接层如果第i+1层是激活层, 注意此时l=m且A实际上是向量={Θi+1∈Rn×m,max(0,sgn(xi+1))∈Rm,如果第i+1层是连接层如果第i+1层是激活层={xi∈Rl,0,如果第i层是连接层如果第i层是激活层
练习题
- 卷积层的前向和后向过程分别是怎样的? (参考卷积神经网络概要)
- 池化层的呢?
- 各种Normalization层呢?
- 循环神经网络的呢?
参考文献
- 链式法则 - Wikipedia
- Tensor Product - Wikipedia
- List of mathematical symbols - Wikipedia